Сегодня поделюсь с Вами очень полезной информацией, которая может быть полезна при наполнении веб сайта и сборе данных. Мы разберемся как спарсить (собрать) данные с веб сайта в нужный столбец excel.
Содержание
Пошаговая инструкция о том, как собрать данные с сайта в эксель
Итак, например, у нам нужно собрать с сайта в таблицу по ссылкам — заголовок h2
=IMPORTXML(A2;»запрос»)
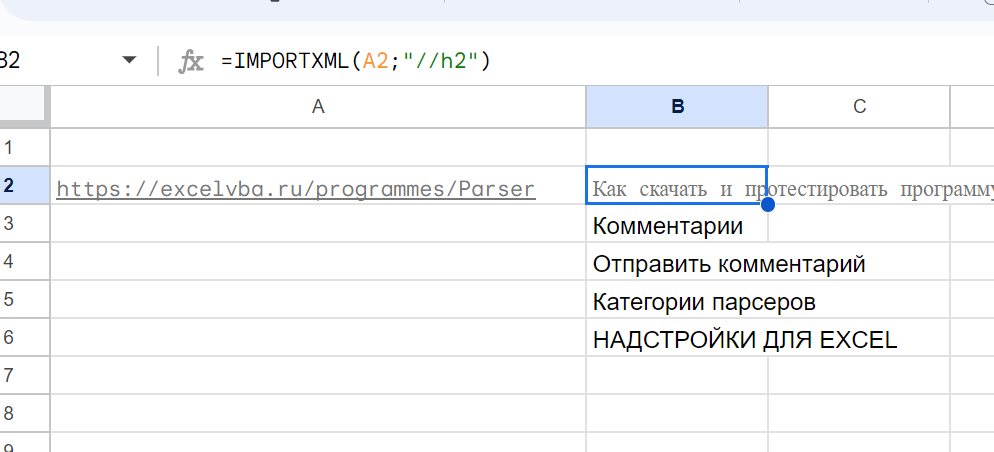
=IMPORTXML(A2;»//h2″)
Нужно собрать title или description — пишем соответствующий запрос =IMPORTXML(A3;»//title») и т.д.
Далее публикую данные с сайта https://awwwake.ru/journal/kak-parsit-v-google-tablicy
Пример использования IMPORTXML. Можно спарсить любые данные.
В данном случае, нашей целью является тег div с определенным классом.
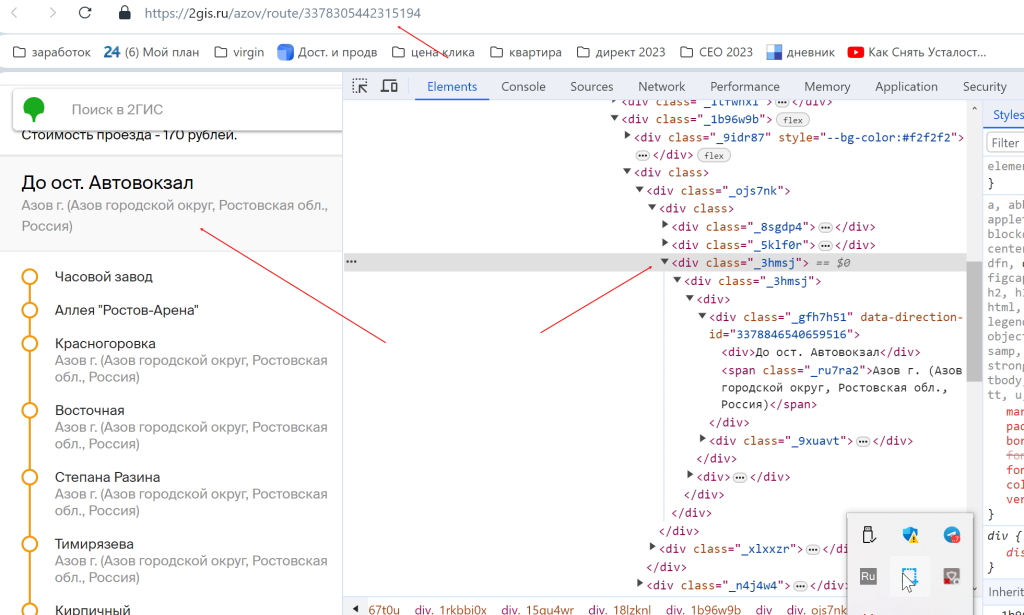
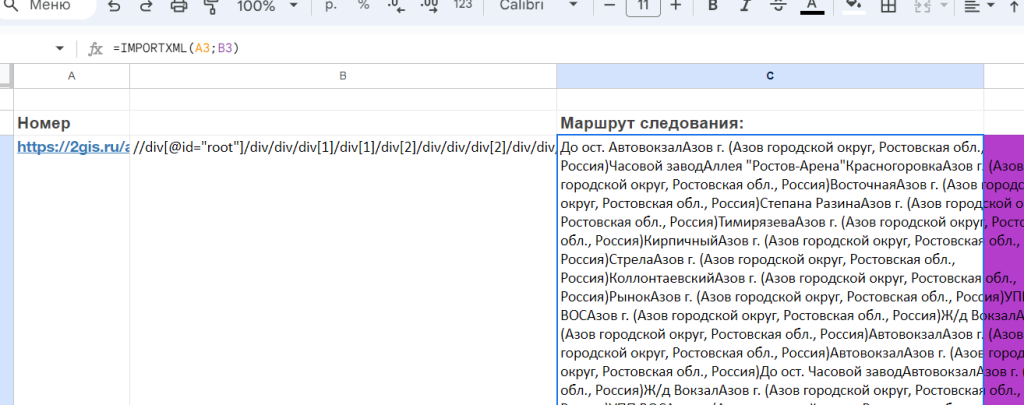
Итак, допустим, у нас задача: спарсить маршрут для маршрутки в таблицу с сайта 2 гис (это просто пример, у вас, конечно, задача своя). Т.е. в одной ячейке у нас ссылка, а в другую надо спарсить содержимое этой ссылки в конкретном месте страницы
Итак, мы переходим по данной ссылке, правой кнопкой нажимаем нужную нам область «посмотреть код элемента» — в каждом браузере по-разному называется — в опере так.
Находим нужный элемент — у меня тег div class=»_3hmsj»
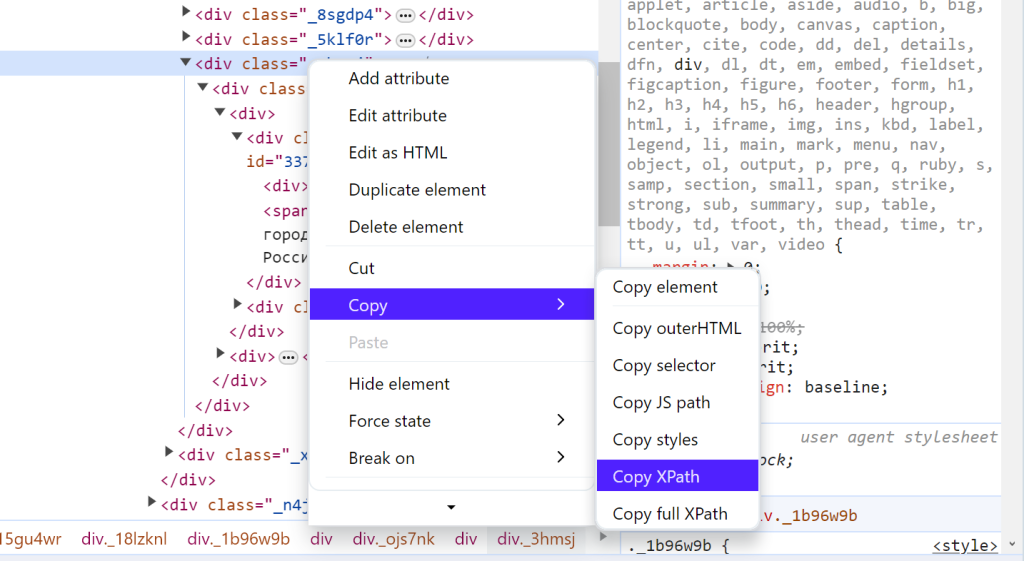
Выбираем правой кнопкой — copy — copy Xpath
Вставляем скопированную конструкцию в дополнительную ячейку эксель и вместо звездочки пишем «div»
Для ячейки с маршрутом следования вставляем формулу =IMPORTXML(A3;B3). Где A3 — ссылка на нужную страницу, B3 — это точное указание места на странице, которую нужно спарсить.
Вот и все! Данные, пусть в неопрятном виде, но загрузились в таблицу. Формулу можно скопировать вниз на остальные ячейки.
IMPORTHTML
Функция импортирует данные со страницы, если они находятся в таблице или списке. Принимает три аргумента:
Ссылку (с указанием протокола, например, https).
Запрос (только два варианта — «table» для таблиц и «list» для списков).
В данном случае прайс-лист на странице оформлен с помощью тега «table» — это видно, если посмотреть исходный код. Поэтому все подтягивается нормально.
А вот на соседней странице этого же сайта, где общий прайс-лист, для верстки использовали тег «div». И IMPORTHTML с параметром «table» уже не справляется. А перебор «list» с разным индексом только вытягивает разные элементы меню.
IMPORTFEED
Импортирует ленту RSS или Atom в гугл-таблицу. Эта функция более интересная, особенно для тех, кто занимается контент-маркетингом.
Параметры:
Ссылка на фид.
Запрос — указываем, какие именно данные нужно загрузить.
(Например, можно прописать «items url» для выгрузки списка ссылок на новые статьи. Или «items title» — для их заголовков, соответственно. А с помощью запроса «items created» можно выгрузить даты публикаций.)
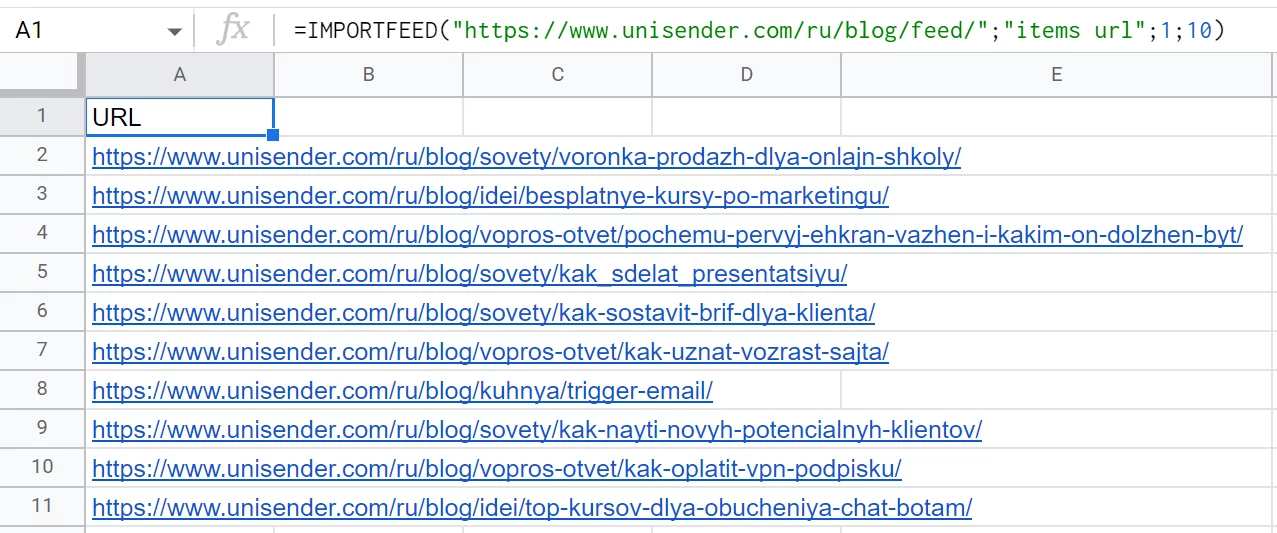
Заголовки — тут нужно указать TRUE (1) или FALSE (0). Если TRUE, то первой строкой будут заголовки столбцов фида: например, «URL» или «Title».
Число объектов — указываем цифру. К примеру, можно вывести в таблицу только последние десять материалов из фида.
Такая формула выводит ссылки на последние 10 статей, которые опубликовали в блоге Unisender. (В соседнем столбце с этих URL уже можно спарсить количество просмотров, чтобы оценить популярность — это рассмотрим позже, в разделе про IMPORTXML и xPath.)


.png)